
Complementaria 8: Cálculo de filas
#
En este tutorial se utilizará la libreria jmarkov en Python para analizar modelos Markovianos de nacimiento y muerte mediante teoría de colas.
Para analizar cada tipo de cola, es necesario identificar su naturaleza. Para familiarizarnos con la librería, realicemos un ejemplo para una cola \(M/M/1\) con tasa de llegada \(3h^{-1}\) y tasa de servicio \(1h^{-1}\). Dado que es una cola con capacidad infinita, utilizaremos el módulo mmk.
from jmarkov.queue.mmk import mmk
Para crear la cola, utilizamos el método mmk que recibe, el número de servidores (k), la tasa de llegadas (arr_rate) y la tasa de servicio (ser_rate).
cola1 = mmk(k=1, arr_rate=3, ser_rate=1)
Antes de calcular medidas de desempeño, debemos revisar si la fila es estable.
cola1.is_stable()
False
Dado que la utilización es mayor a 1, el sistema no alcanza estado estable. Para continuar con el ejercicio, intercambiaremos los parámetros del modelo para que sea estable. Ahora la tasa de llegada será \(1h^{-1}\) y la tasa de servicio \(3h^{-1}\).
cola1 = mmk(k=1, arr_rate=1, ser_rate=3) # Creamos el objeto tipo cola
cola1.is_stable() # Revisamos estabilidad
True
Con una fila estable, es posible obtener medidas de interés utilizando los métodos:
Comando |
Operacion |
|---|---|
|
Calcula el número promedio de entidades que hay en el sistema. |
|
Calcula el número promedio de entidades que hay en fila. |
|
Calcula el número promedio de entidades que hay en servicio. |
|
Calcula el tiempo promedio que permanece una entidad en el sistema. |
|
Calcula el tiempo promedio que permanece una entidad en cola. |
|
Calcula el tiempo promedio que permanece una entidad en servicio. |
Revisemos el uso de algunas de ellas.
Por ejemplo, si nos interesa conocer el número promedio de entidades en el sistema, utilizamos el comando de la siguiente manera:
num_promedio_entidades = cola1.mean_number_entities()
num_promedio_entidades
0.49999999999999983
Por otro lado, si es de interés conocer el tiempo promedio que las entidades permanecen en fila, se utiliza el siguiente comando:
tiempo_promedio_fila = cola1.mean_time_queue()
tiempo_promedio_fila
0.16666666666666666
A continuación, resolveremos los ejercicios propuestos en el archivo Complementaria 8 (Q).pdf que se encuentra en Bloque Neón.
Problema 1: FoodTruck
Este problema corresponde a una cola \(M/M/2\) debido a que se tienen dos servidores. La tasa de llegada es de \(80 \frac{personas}{hora}\) y la tasa de servicio es de \(50\frac{personas}{hora}\). Así, definamos los parámetros y creemos el objeto tipo cola.
foodtruck = mmk(k=2, arr_rate=80 ,ser_rate=50)
Literal a
En el literal a, se debe hallar el número esperado de clientes en estado estable. Para esto, verificamos que el sistema alcance estado estable.
foodtruck.is_stable()
True
Como el sistema es estable, podemos hallar el número esperado de clientes en el Food Truck \((L)\).
clientes = foodtruck.mean_number_entities()
clientes
4.444444420905357
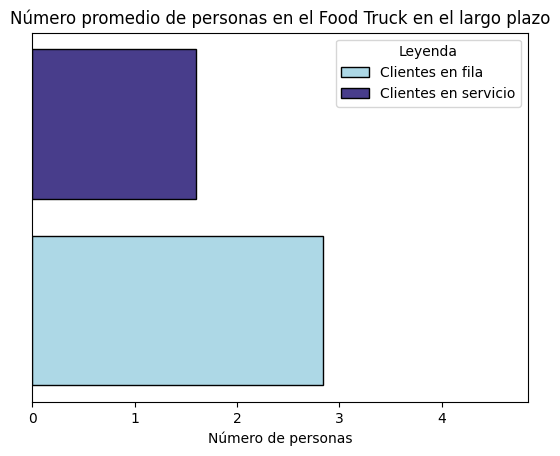
Así, en promedio en el Food Truck habrá 4.44 personas en estado estable.
Para un tomador de decisiones puede ser de interés conocer cuantas de estas personas están en fila y cuantas siendo atendidas. Calculemos el número de personas en fila y en servicio.
clientesFila = foodtruck.mean_number_entities_queue()
clientesFila
2.844444421358036
clientesServicio = foodtruck.mean_number_entities_service()
clientesServicio
1.6
Ahora, realizaremos una gráfica comparativa para el número promedio de personas en fila y el número promedio de personas en servicio.
import matplotlib.pyplot as plt
import numpy as np
positions = np.arange(len(["Clientes en fila", "Clientes en servicio"]))
plt.barh(
y=positions[0],
width=clientesFila,
color="lightblue",
edgecolor="black",
label="Clientes en fila"
)
plt.barh(
y=positions[1],
width=clientesServicio,
color="darkslateblue",
edgecolor="black",
label="Clientes en servicio"
)
plt.yticks([])
plt.xlabel("Número de personas")
plt.title("Número promedio de personas en el Food Truck en el largo plazo")
plt.xlim(0, max([clientesFila, clientesServicio]) + 2)
plt.legend(["Clientes en fila", "Clientes en servicio"], title="Leyenda")
# Mostrar gráfico
plt.grid(axis='x', linestyle='')
plt.show()
Literal b
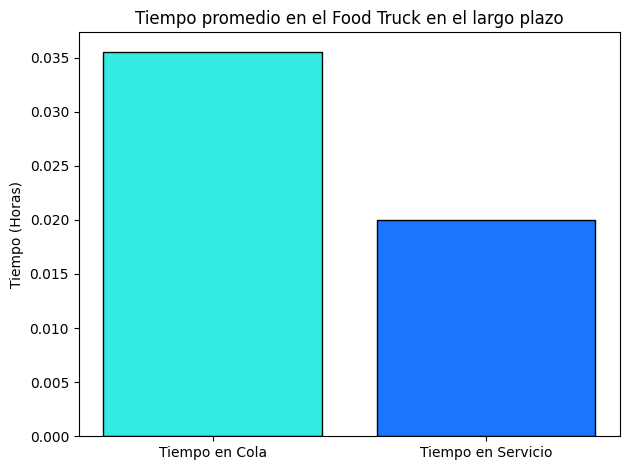
Para el literal b, se debe hallar el tiempo en horas que un cliente debe esperar en fila para ser atendido.
tiempoFila = foodtruck.mean_time_queue()
tiempoFila
0.03555555526697545
De igual modo, construiremos una gráfica comparativa entre el tiempo de servicio y el tiempo en fila. Entonces, debemos calcular el tiempo en fila y el tiempo en servicio.
tiempoServicio = foodtruck.mean_time_service()
tiempoServicio
0.02
etiquetas = ["Tiempo en Cola", "Tiempo en Servicio"]
tiempos = [tiempoFila, tiempoServicio]
plt.bar(
x=etiquetas,
height=tiempos,
color=['#34EBE1', '#1A76FF'],
edgecolor="black"
)
plt.title("Tiempo promedio en el Food Truck en el largo plazo")
plt.xlabel("")
plt.ylabel("Tiempo (Horas)")
plt.tight_layout()
plt.show()
Literal c
Para el literal c, se debe hallar la fracción del tiempo que Daniela se encuentra ociosa.
Daniela estará ociosa cuando no haya personas en el sistema y la mitad del tiempo cuando haya una persona en el sistema. Esta fracción del tiempo corresponde a: \(\pi_0 + 0.5 \cdot \pi_1\)
Para hallar las probabilidades en estado estable utilizamos el atributo probs, el cual nos devuelve un vector que guarda la probabilidad de estar en cada uno de los estados del sistema, en el largo plazo.
estado_estable = foodtruck.probs
Luego, podemos hacer el cálculo de la siguiente forma:
daniela_ociosa = estado_estable[0] + 0.5*estado_estable[1]
daniela_ociosa
0.2
Esto quiere decir que, el 20% del tiempo, Daniela estará ociosa.
Literal d
Finalmente, para el literal d, se debe hallar la fracción del tiempo que Daniela se encuentra ociosa dado que se contrató un tercer empleado.
Este problema corresponde a una cola \(M/M/3\), manteniendo las mismas tasas de llegada y de servicio. Así, debemos crear un nuevo objeto tipo cola.
foodtruck2 = mmk(k=3, arr_rate=80, ser_rate=50)
Con la inclusión de un tercer servidor, Daniela estará ociosa cuando no haya personas en el sistema, dos tercios del tiempo cuando haya solo una persona en el sistema y un tercio del tiempo cuando haya dos personas en el sistema. Siguiendo la lógica del literal anterior, se puede calcular esta proporción del tiempo para cada cantidad de personas en el sistema, de la siguiente manera:
\(\text{Proporción del tiempo desocupada con i personas en el sistema} = \pi_i \cdot \frac{s-i}{s},\ \forall i < s\)
Entonces, la proporción del tiempo que Daniela estará desocupada se calcula mediante la siguiente expresión:
\(\sum_{i=0}^{s-1} \pi_i \cdot \frac{s-i}{s}\)
Procedemos ahora a revisar estabilidad:
foodtruck2.is_stable()
True
Calculamos las probabilidades en estado estable:
foodtruck2._solve_bd_process(3)
estado_estable2 = foodtruck2.probs
Encontramos la métrica de interés:
daniela_ociosa2 = 0
for i in range(0, 3):
daniela_ociosa2 += estado_estable2[i]*((3-i)/3)
daniela_ociosa2
0.4666666666666667
Notemos que, si calculamos la utilización se obtiene:
utilizacion = 80/(3*50)
utilizacion
0.5333333333333333
1-utilizacion
0.4666666666666667
Lo que quiere decir que, si \(\rho_s\) es igual a la propoción del tiempo que el sistema está siendo utilizado, \(1-\rho_s\) es la proporción del tiempo que uno de los servidores está desocupado.
\(\sum_{i=0}^{s-1} \pi_i \cdot \frac{s-i}{s} = 1 - \rho_s\)
Problema 2: Peluquería
De acuerdo al enunciado del Problema 2, la peluquería tiene una capacidad de 10 clientes en total, y tiene una única servidora. Por lo tanto, el sistema se puede modelar como una cola \(M/M/1/G/10/\infty\). De este modo, se utiliza el módulo mmkn donde \(n=10\). Se conoce que la tasa de entrada es de \(\frac{1}{3}m^{-1}\), y la tasa de servicio es de \(\frac{1}{12}m^{-1}\).
from jmarkov.queue.mmkn import mmkn
La función mmkn recibe el número de servidores (k), tasa de llegadas (arr_rate), tasa de servicio (ser_rate) y la capacidad del sistema (n).
peluqueria = mmkn(k=1, arr_rate=1/3, ser_rate=1/12, n=10)
Literal a
Se debe hallar el número de cortes de pelo que se realizan en una hora. Esto corresponde a la tasa efectiva de entrada al sistema. En Python, podemos llamar el método _solve_db_process() para resolver el proceso de nacimiento y muerte, encontrando las probabilidades en estado estable y luego llamando el atributo eff_arr_rate.
peluqueria._solve_bd_process()
tasa_efectiva_minutos = peluqueria.eff_arr_rate
tasa_efectiva_horas = tasa_efectiva_minutos*60
tasa_efectiva_horas
4.999996423720461
Esto quiere decir que, en promedio en la peluquería se atienden 4.99 personas en una hora.
Literal b
Ahora, se debe hallar el tiempo promedio en horas que un cliente permanece en la peluquería.
tiempo_total_minutos = peluqueria.mean_time_system()
(tiempo_total_minutos/60)
1.9333352406837852
Universidad de los Andes | Vigilada Mineducación. Reconocimiento como Universidad: Decreto 1297 del 30 de mayo de 1964. Reconocimiento personería jurídica: Resolución 28 del 23 de febrero de 1949 Minjusticia. Departamento de Ingeniería Industrial Carrera 1 Este No. 19 A 40 Bogotá, Colombia Tel. (57.1) 3324320 | (57.1) 3394949 Ext. 2880 /2881 http://industrial.uniandes.edu.co